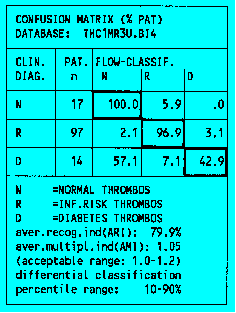
Confusion Matrix
Explanation of Parameters of the Classification Masks

Reclassification of the Learning Set

Parameters of One of the Databases

- The print output of the CLASSIF1 learning procedure LRNTHROM comprises the percent and sample confusion matrices, the reference classification masks and the reclassification list of the leaning set.
- The normal and myocardial risk patients are well recognised from the activation antigen pattern of the peripheral blood thrombocytes while diabetic patients are less well identified.
- The chosen database columns in the reference classification masks derive from all four measurements. The IgG, CD62, CD63 and thrombospondin measurements contribute 2, 2, 3 and 2 database columns. The chosen database columns represent all antibody intensity or antibody surface density values. Percent frequency values of antibody negative or positive cells, in contrast, were not chosen because they were less discrminative. This underlines the importance of the calculation of relative parameter intensity values in flow cytometric list mode and histogram evaluation.
- The reclassification list of the learning set shows that the sample classification masks do not exhibit systematic differences with the increasing number of patients i.e. the immunephenotype measurements were of stable quality over the collection period of the samples which was about one year.
- The reclassification list further shows that triple matrix classifiers are inherently error tolerant because correct classification results are obtained in most instances although the positional coincidence of the: +, - and 0 characters with the reference classification masks is frequently substantially lower than 1.0
 |
 |
 |
 |